“Another month, another Power BI Desktop update” as Guy(s) in a Cube use to say.
Power BI Desktop October 2018 update brings in quite a few updates, with one thing being my favorite as I always do/check it manually when working with new data: Data Profiling. For more info and how to enable it, visit Microsoft’s official Power BI blog post or the detailed post from Matt Allington on https://exceleratorbi.com.au.
Ok, I don’t want to make it a long post, so here’s the thing: one of the Data Profiling feature is “Column distribution”.
Column Distribution allows you to get a sense for the overall distribution of values within a column in your data previews, including the count of distinct values (total number of different values found in a given column) and unique values (total number of values that only appear once in a given column).
So, distinct and/or unique. For anyone else these 2 words may seem similar, but for Data Guys like us, these are 2 different things (just like empty and null 🙂 ). Still confused? Here’s a very simple example to clear things up:
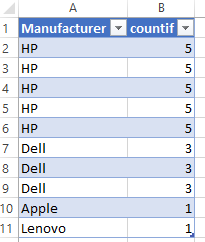
Let’s say we have a small company with 10 employees using 10 laptops from different Manufacturers: HP, Dell, Apple and Lenovo.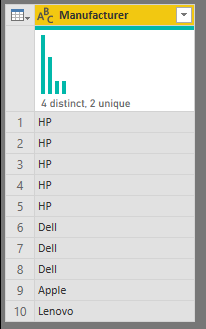
Distinct: We have laptops from 4 different Manufacturers (HP, Dell, Apple and Lenovo) aka “total number of different values”, regardless of how many of each we have.
Unique: We have only 2 laptops that nobody else have in our company (one from Apple and another one from Lenovo) aka “total number of values that only appear once”.
Thinking legacy, here’s the same thing in Excel, using countif or countifs.